1. Motivation
The flood of daily publications in Computer Vision and AI poses a challenge for anyone wanting to consume research: identifying valuable insights without spending hours sifting through papers. Traditional keyword or author searches often miss nuanced context or fail to adapt to evolving interests and can miss relevant papers. Tools such as Litmap, Connected Papers or Semantic Scholar fall short if it's about the most recent research. I aimed to solve this by creating a system that not only automates the selection process but also learns from user preferred topics. By combining AI-driven filtering with human feedback loops, this tool empowers a user to focus on innovation rather than information overload.
2. Approach
2.2 Overview
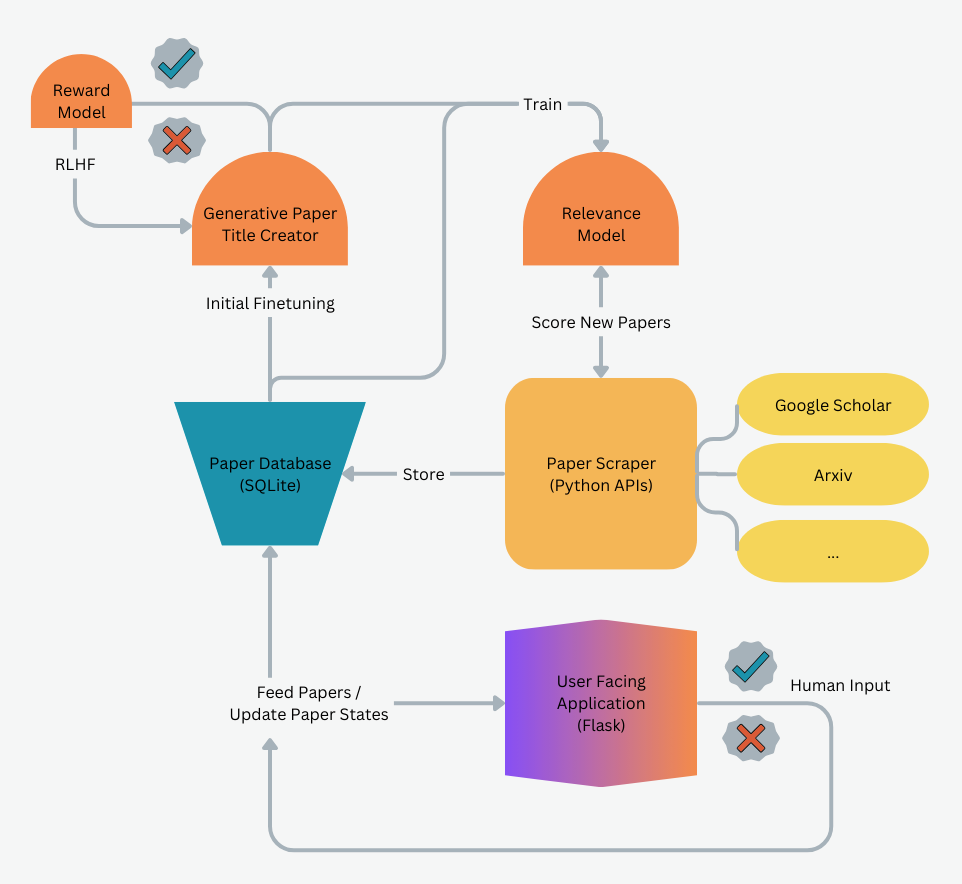
The system consists of five main components (as seen in Fig. 1):- Paper Database
- Paper Scraper
- Relevance Model
- Generative Paper Title Creator
- User Facing Application
🗂️ Paper Database
To ensure the entire process remains independent of external sources, I decided to build my own paper
database. This database stores essential paper metadata along with links to the PDFs, facilitating the
easy ingestion of new papers and ensuring that duplicates are not ingested if they appear in multiple
sources. Additionally, the custom metadata it supports is crucial for tagging and training
purposes.
The paper metadata stored in the database, which is also responsible for the database definition, looks
like this:
@dataclass
class Paper:
title: str
authors: List[str]
conferences: Optional[str]
comment: str
abstract: str
categories: List[str]
paper_id: str
pdf_url: str
pdf_file: Optional[str]
published: datetime
source: str
score: Optional[float]
selected_review: Optional[bool]
selected_review_date: Optional[datetime]
📑 Paper Scraper
The paper scraper is tasked with discovering and ingesting new research publications from various online
sources. It is designed to be highly flexible, enabling the integration of multiple sources. Currently,
only sources with a clean Python API, such as arXiv and Google Scholar, have been incorporated.
Operating independently of the curator and user application, the scraper periodically updates the
database with new papers, ensuring the system stays current with the latest research.
🔍 Relevance Model
The centerpiece of the system is the relevance model, which serves as a learned curator. Its primary
role is to score papers based on their metadata, ensuring that only relevant papers reach the user while
filtering out noise. The process is straightforward: paper metadata is input, and a relevance score is
output.
Scoring is handled by a fine-tuned language model that classifies metadata, as detailed in the "Scoring"
section below. The scorer is implemented in Python, utilizing PyTorch for the model component. This
curator also interacts with the user through the application, incorporating user feedback on relevancy
into the model to continuously improve its performance.
📝 Generative Paper Title Creator
Due to the overwhelming noise compared to relevant papers, the dataset used to fine-tune the relevance
model is highly imbalanced, making it challenging to train a model that effectively generalizes to user
preferences. To tackle this, I use a generative approach to create artificial paper titles and
abstracts, which the user can rate for relevance. This feedback is then incorporated back into the
generative model using Reinforcement Learning with Human Feedback (RLHF) to improve the quality of
generated titles and abstracts. Additionally, true papers identified as relevant from the paper scraper
are augmented with these generated titles to further fine-tune the relevance model.
🌐 User Facing Application
Finally, the application includes a user-facing frontend that enables users to inspect and open papers,
as well as reclassify them based on their relevance. This feedback is then integrated back into the
learned paper curator. Built with Flask, the application features a straightforward web interface that
provides all necessary UI elements while seamlessly connecting to the curator and database through
Python.
2.2 Scoring
The core efficiency and value of the system hinges on accurately scoring the relevance of papers, which ultimately depends on the user's specific interests. Fortunately, I had the advantage of using a simpler system for over a year that relied solely on keyword and author-based To implement this, I used a dictionary of word-value pairs. Whenever one of these words appeared in the title, its corresponding value was added to the overall score. . While this approach provided a sufficient foundation to experiment with a more sophisticated, learned approach.
2.2.1 Model Finetuning
I opted for a straightforward, language-based approach to paper classification, leveraging a combination
of the title, abstract, authors, and conference information. The chosen model,
ModernBERT1,
is used for
binary text classification. The input to the tokenizer is a concatenation of the title, authors, and
abstract in the format: input = f"{title} | {authors} | {abstract}". To accommodate the
model's maximum
input length of 1024 characters, the abstract has been preprocessed to remove stop words.
Given the dataset's significant imbalance—where the majority of papers are irrelevant—I employed undersampling for the negative class and adjusted class weights during loss computation. With approximately 800 positive and 40,000 negative samples, the precision/recall metrics and the ROC curve are provided below. Notably, achieving a high recall for positive samples is prioritized, as missing relevant papers is critical, whereas lower precision is more acceptable. For negative samples, the inverse holds true.
The support for the positive class is very limited, with only 200 samples, which makes the results highly sensitive to the sampled cases. However, to minimize the risk of overfitting to a specific test/training distribution, the fine-tuning process was repeated 10 times with different test/training splits. results on the evaluation dataset:
precision recall f1-score support
0 0.99 0.91 0.95 11795
1 0.13 0.82 0.23 200
accuracy 0.91 11995
macro avg 0.56 0.86 0.59 11995
weighted avg 0.98 0.91 0.94 11995
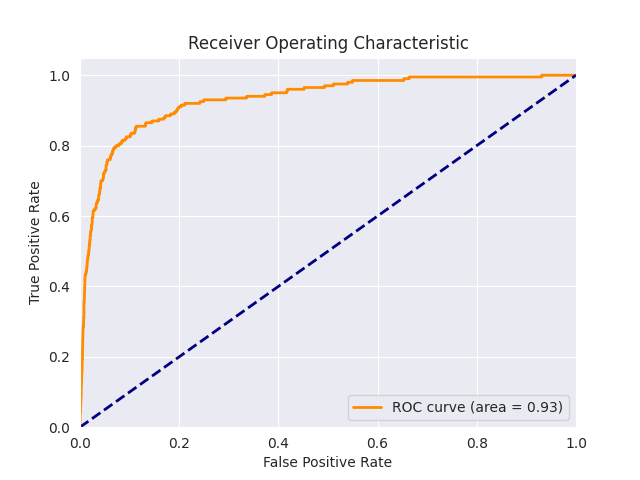
These results demonstrate that, despite the imbalanced dataset, the fine-tuned model effectively filters out approximately 90% of irrelevant papers while missing 20% of true positive relevant ones. By lowering the classification threshold for relevance, the model can achieve a 90% recall of relevant papers but reduces noise by only 80%. It's crucial to prioritize capturing relevant papers, as missed ones are challenging to recover, whereas removing 80% of irrelevant content already provides significant value to the user.
After fine-tuning the relevance model, I apply it to the entire dataset and review the misclassified papers to identify any that may require correction. This process is repeated weekly, alongside incorporating newly scraped papers from the sources, ensuring that no relevant It's important to avoid missing relevant papers, so the criteria for relevance are periodically relaxed to allow for manual review of a broader set of data. This approach prevents the model from collapsing into overly narrow predictions. are overlooked.
2.2.2 Explore Relevancy Through Generative Paper Creation and RLHF
Although the initially fine-tuned classification model offers value, it is hindered by the inherent challenges of the task—namely, the dataset imbalance and the difficulty of predicting paper relevancy based solely on the title and abstract. To better capture user preferences and explore a wider range of paper (and abstract) possibilities, I developed a generative paper creation system that augments the dataset, providing additional training material for the classifier Heavily inspired by the AI-Scientist from sakana.ai3. .
In the first phase, a generative model (GPT-22 in that case) is
trained on
the full paper database and then on a limited set of relevant paper titles
to produce new, synthetic titles that resemble real-world
relevant papers. These generated papers are
A simple TUI has been built with curses (see code) to do this to have a fast iteration
cycle.
by the user with relevancy
scores ranging from -1 to 10. Titles (and abstracts) that are deemed unrealistic are assigned a score of
-1, while those rated
as irrelevant receive a 0, and those considered highly relevant are given a 10. A reward model is then
trained on these annotations, guiding the generative model using RLHF to produce more meaningful labels.
This
iterative process allows the user and the model to explore new topics and paper ideas that could be
relevant. To further diversify the generated titles, specific topics can be included in the prompt. The
process continues until 95% of the generated papers are labeled as relevant by the user, with the number
of generated papers reaching a size comparable to the ground truth positive labels (~1000).
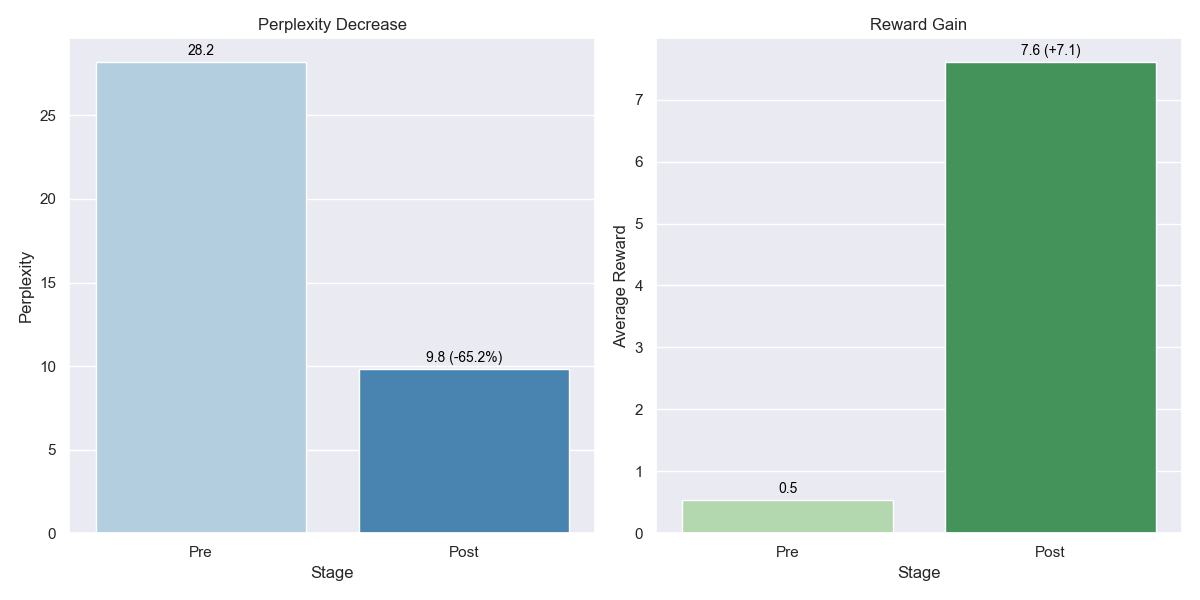
Through the initial generator finetuning with the whole (true) dataset, the models perplexity is reduced from 28 down to 10 which shows good alignment with the ground truth. Examples of the generated titles are shown further below. Another evaluation of the system is looking at the averaga reward before and after the RLHF training. The finetuned generator is able to produce output that increases the average reward from 0.5 to 7.5 using the initially trained reward model.
Small sample of generated titles after initial finetuning:
DiffuK-Vid: Diffusion Video Model for High-fidelity Talking Face Video Generation
Vision-based Occupancy Prediction Based on Geometric Priors
Segment Any Mask
Adaptive Data Scaling for Efficient Object Detection
GaussianFormer: 3D Gaussian Splatting Transformer with Local-Global Fusion
GAMMA-Net: Gated Multimodal Adapter for Efficient Multimodal Action Recognition
DiffusionFormer: Boosting Vision Transformers with Diffusion Transformers
This system is capable of adapting to the For example, over the past year, there's been a shift from GANs, model scaling, and federated learning towards multi-modality, foundation models, and model alignment, reflecting the growing focus on integrated systems and improving AI alignment with human values. preferences of the user over time, as it is designed to run periodically and is integrated with the weekly paper updates. By continuously incorporating user feedback and relevancy annotations, the model refines its understanding of the user's interests and adjusts its generative process accordingly. This dynamic approach ensures that the dataset remains aligned with the user's shifting preferences, allowing the system to generate more relevant and tailored paper ideas as it progresses.
2.3 Interface
The interface features a simple UI with two main sections: the overview and the review page. The overview displays all reviewed and selected papers, organized by I chose to use weekly cycles for aggregating the papers, as this provides a good balance between recency and manageable volume. , along with relevant metadata.
Overview Page
The main feature of the overview page is the week selector, which displays all relevant papers for a
specific week. Clicking on a paper reveals the abstract, along with additional meta-information and a
direct link to the PDF stored on disk for reading and annotation.
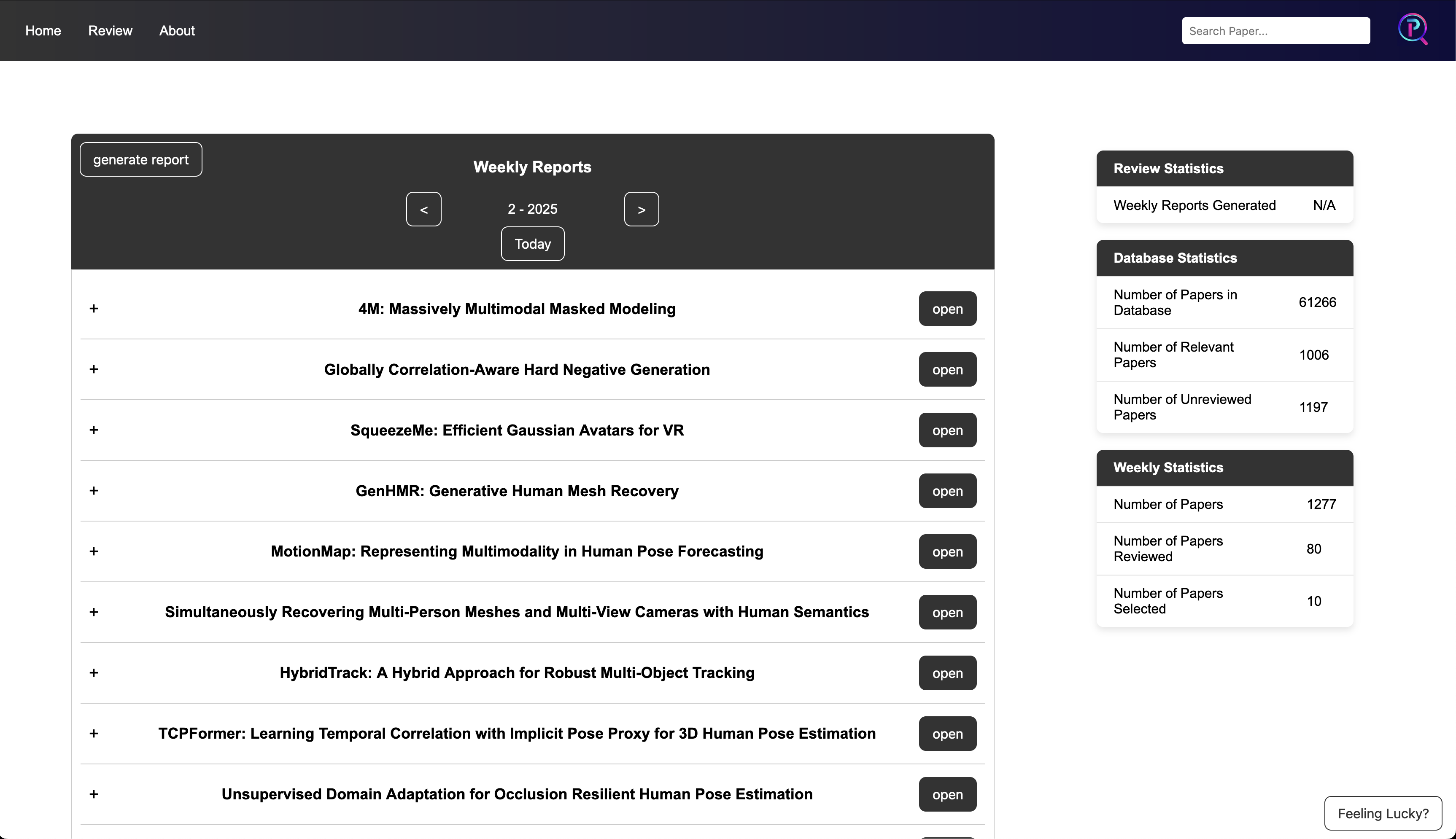
Review Page
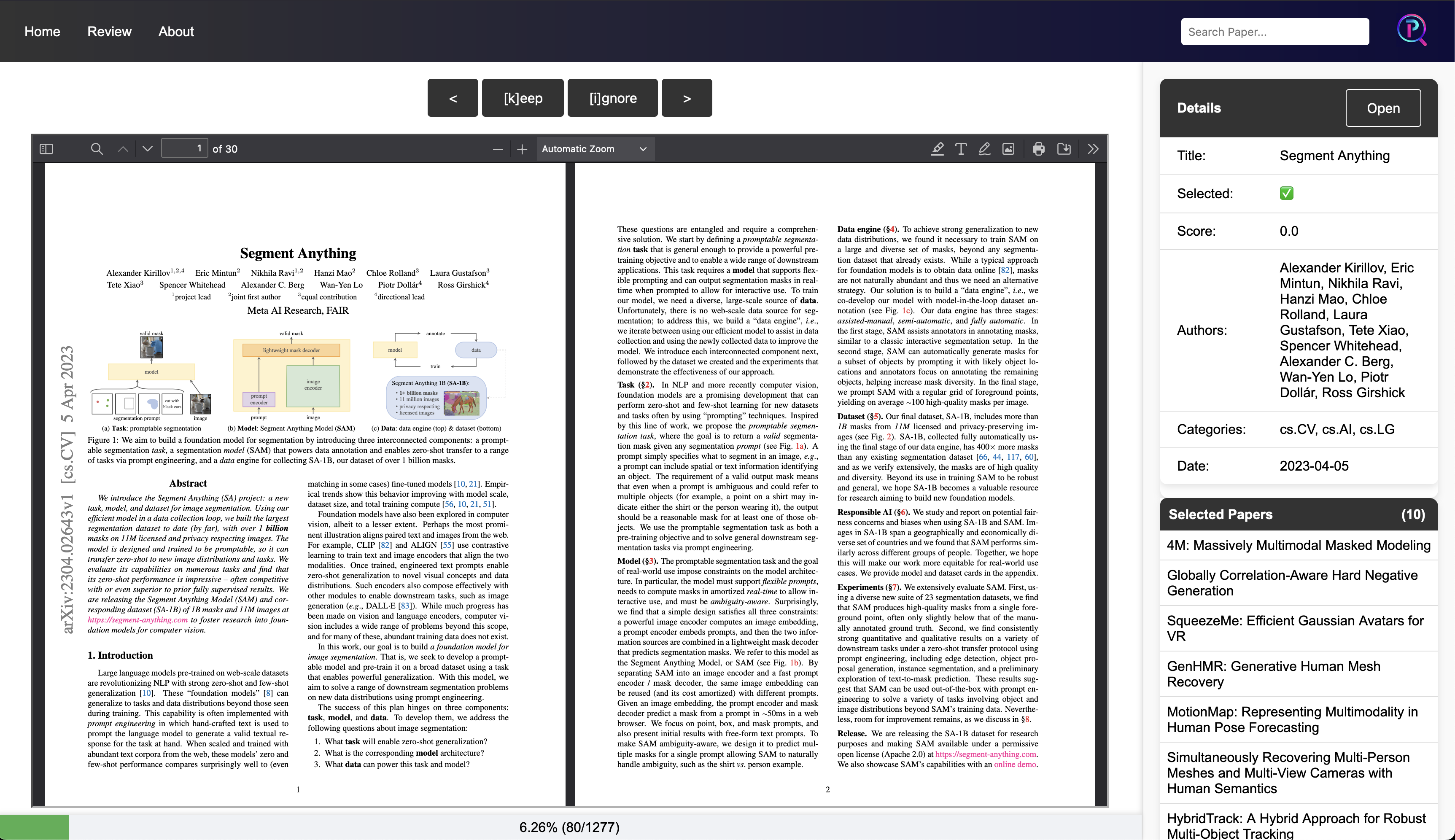
The review page features centrally located navigation and paper selectors (ignore or keep), which can
also be accessed via hotkeys. On the left side, you'll find metadata for the current paper, as well as a
list of all papers selected for the week. In the center, the paper itself is
To ensure fast loading when switching between papers, the application caches PDFs on disk.
in an iframe.
This layout enables efficient paper review using only the keyboard, while still allowing quick access to
the full paper when necessary.
3. Conclusion
This paper curation tool addresses the challenge of managing the overwhelming volume of research in (for example) Computer Vision and AI. By automating the process of discovering and filtering papers, it ensures that users only see the most relevant work. Combining fine-tuned language models with reinforcement learning from human feedback and generative techniques, the system adapts to user preferences and evolves over time. This approach not only saves time but also makes it easier to stay up-to-date with cutting-edge research, providing a more efficient way to engage with the growing body of knowledge in the field. The approach is easily adaptable and extensible to other sorts of inputs, ideas, rewards or sources.
Building a functional product with language models and reinforcement learning was a significant learning experience for me. This system has become an indispensable daily tool, greatly enhancing my efficiency in staying updated with the latest research.
3.1 Limitations and Future Work
There are several limitations to the current system, and I’ll begin with the most significant ones. The model's performance heavily relies on the quality of annotations as well as the biases introduced by the generator, reward model, and relevance model. Acquiring annotations, ensuring their quality and comparing them against the full dataset of existing papers is critical, but this process can be time-intensive. Second, the system currently utilizes only a subset of available metadata, focusing primarily on titles and abstracts. It cannot realistically generate authors relevant outside of those already included. Additional metadata, such as keywords, conferences, or associated labs/companies, could significantly enhance the system's capabilities. While the generative model effectively addresses the underrepresented positive class and explores potential paper ideas, a GPT-2-like model is limited in its ability to generate truly novel ideas and meaningful paper titles. A larger or more specialized model might be more suitable for these tasks.
Several possible extensions could enhance the current system. One option is to implement automatic paper summarization, making papers easier to digest and situating them within a broader context. Expanding paper and metadata scraping efforts would also create a more comprehensive dataset. Finally, developing a system capable of generating novel ideas by combining insights from different papers—much like researchers draw inspiration from others’ work—could be a valuable addition, enabling deeper exploration of the space of possible ideas.